FAST+EFFICIENT 8-BIT HW CASE STUDIES DOWNLOAD
Fast, Energy-Efficient Deep Neural Net
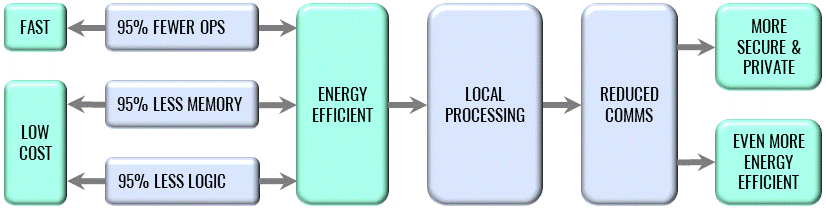
The Lt-Wt (Lightweight) net is our fast and energy-efficient deep neural net that can be embedded directly into resource-constrained IoT devices. These devices will not need to broadcast any data as they will be able to do their processing locally. This will result in improved security and privacy.
The Lt-Wt net requires 95% fewer ops, 95% less memory, and 95% less logic as compared with the conventional neural net (CNN), making it suitable for fast and economical ASIC, FPGA, or 8-bit microcontroller implementations. Its inference ability is similar to the CNN.
The Lt-Wt net can approximate arbitrary continuous functions with any accuracy. It requires modest storage and has a multiplication-free forward pass, rendering it suitable for deployment on inexpensive hardware. The Lt-Wt learning process automatically drops insignificant inputs, unnecessary weights, and unneeded hidden neurons. The sparse weight matrices of the Lt-Wt net loosen the coupling among the layers, making the Lt-Wt net more tolerant to the failure of individual neurons.
The learned information in CNN is distributed over all weights. In a Lt-Wt net, the picture is less fuzzy and the localized nature of computation is much more obvious due to the presence of a large number of zero-valued weights. For image processing, a CNN does not scale well with increases in the resolution of the images due to the fully-connected structure of the net. A Lt-Wt net, on the other hand, scales much better due to the sparsity of its weight matrices.
The small magnitude of the Lt-Wt net weights should result in smooth mappings and the small number of non-zero weights should result in low generalization error.
The Lt-Wt net has been successfully tested with up to 16 hidden layers and 4.4 million weights on problems having input vectors consisting of tens of thousands of elements.
Implementation in 8-bit Hardware
The inputs are mapped to an 8-bit fixed-decimal representation. All neurons have 8-bit outputs and all arithmetic is integer only. The arithmetic ops consist of additions and subtractions only. The activation function is implemented as a 2 kB lookup table.
The executable Lt-Wt net consists of the following elements:
- RAM (input and outputs)
- Random access ROM for the lookup table
- Read-once ROM to hold the network definition
- Control logic
Configuring these elements for fast execution on an 8-bit microcontroller or efficient implementation on an FPGA is straightforward. An end-to-end 16-bit implementation of the Lt-Wt Net on a Cortex-M4 requires only 0.1 kB of code. This enables, in the case of the Human Activity Recognizer, operation in the sub-µW range on microprocessors and at 10-20% of that on FPGAs.

Case Studies
Problem
Predict failure of the Air Pressure System (APS) in heavy Scania trucks based on sensor data.*Data
There are 170 features and a single yes/no outcome that needs to be predicted. The training dataset consists of 60 k instances, out of which 59 k are of the negative class, 1 k of positive class, and 850 k values are missing. The test dataset consists of 16 k instances and 229 k values are missing.Training Results
The trained Lt-Wt net had an F1 score of 0.73, recall 0.68, precision of 0.79, and accuracy 0.99 on test data.Comparison With 32-Bit Floating-Point CNN
The tiny number of fetches (1/72 bytes) and additions (1/14) combined with integer-only arithmetic, lack of multiplications, and 8-bit data flows results in a very fast and highly energy-efficient Lt-Wt net. Moreover, the tiny memory footprint makes it possible to place the whole network in the L1-cache of certain microprocessors.
- Reduced number of memory fetches (1/108 in terms of bytes)
- Reduced number of arithmetic (1/27) and other operations
- Reduced number of bytes fetched (1/108)
- No multiplications, floating-point or otherwise
- Integer-only additions and subtractions
- Lower RAM (1/4) and ROM (1/26) requirement
- 8-bit input-neuron, neuron-neuron, and neuron-output data paths
- No multiplier, floating-point or otherwise
- Integer-only adder
Problem
Human activity recognition based on triaxial acceleration and triaxial angular velocity readings from a smartphone attached to the waist.*Data
There are 561 features and six possible outputs: laying; sitting; standing; walking; walking downstairs; walking upstairs. The features are based on the time-series data from the two sensors, and include time domain as well as frequency domain components. The training dataset consists of 7,352 instances, out of which 986 represent the minority class and 1,407 the majority class. The test dataset consists of 2,947 instances, out of which 420 represent the minority and 537 the majority class.Training Results
The trained Lt-Wt net had an F1 score, recall, precision, and accuracy equal to 0.95 on test data.Comparison With 32-Bit Floating-Point CNN
The tiny number of fetches (1/66 bytes) and additions (1/26) combined with integer-only arithmetic, lack of multiplications, and 8-bit data flows results in a very fast and highly energy-efficient Lt-Wt net. Moreover, the tiny memory footprint makes it possible to place the whole network in the L1-cache of certain microprocessors.
- Reduced number of memory fetches (1/66 in terms of bytes)
- Reduced number of arithmetic (1/52) and other operations
- Reduced number of bytes fetched (1/66)
- No multiplications, floating-point or otherwise
- Integer-only additions and subtractions
- Lower RAM (1/7) and ROM (1/48) requirement
- 8-bit input-neuron, neuron-neuron, and neuron-output data paths
- No multiplier, floating-point or otherwise
- Integer-only adder
**Human Activity Recognition with Smartphones
Problem
Predict failure of aircraft engines based on data collected during run-to-failure simulations*Data
Inputs from 21 sensors, including those for temperature, pressure, RPM, fuel flow, fuel-air ratio, and bleed-enthalpy measurements, are used to make one of three possible predictions: engine failure in 1-15,16-30, or 30+ operational cycles. The training and test datasets consist of 21 k and 13 k instances, respectively.Training Results
The trained Lt-Wt net had an F1 score, recall, precision, and accuracy equal to 0.95 on test data.Comparison With 32-Bit Floating-Point CNN
The lower number of fetches (1/3 bytes) and additions (1/1.2) combined with integer-only arithmetic, lack of multiplications, and 8-bit data flows results in a very fast and highly energy-efficient Lt-Wt net. Moreover, the tiny memory footprint makes it possible to place the whole network in the L1-cache of certain microprocessors.
- Reduced number of memory fetches (1/3 in terms of bytes)
- Reduced number of arithmetic (1/2.5) and other operations
- Reduced number of bytes fetched (1/3)
- No multiplications, floating-point or otherwise
- Integer-only additions and subtractions
- Lower RAM (1/2) and ROM (1/2) requirement
- 8-bit input-neuron, neuron-neuron, and neuron-output data paths
- No multiplier, floating-point or otherwise
- Integer-only adder
**Predictive Maintenance: Simulated aircraft engine run-to-failure
Downloads
- Lightweight Neural Networks pdf arxiv preprint
- Case Study: Real-Time Condition Monitoring pdf
- Case Study: Predictive Maintainenace pdf
- Case Study: Wearable Intelligence pdf